NLP-Cyber-Harm-Detection
NLP Fraud/Scam Detection Baseline Models
A comprehensive implementation for fraud and scam detection using advanced Natural Language Processing techniques. This project leverages state-of-the-art transformer-based models for accurate fraud classification with explainable AI-powered reasoning. The latest BART Joint Model provides simultaneous classification and detailed contextual explanations in a single unified architecture.
📁 Repository
🔗 GitHub Repository: https://github.com/RockENZO/NLP-Cyber-Harm-Detection.git
🎯 Project Overview
This project implements advanced models for detecting fraudulent content (scams, phishing, spam) in text data using state-of-the-art transformer architectures. Key approaches include:
Unified Classification + Reasoning (FLAN-T5)
We added a unified, text-to-text approach using FLAN-T5 that produces both the class label and a concise explanation in a single generation. This works directly with your existing CSV (final_fraud_detection_dataset.csv) that has text and detailed_category columns. If your dataset also has rationale fields such as explanation or rationale, the trainer will use them; otherwise, it auto-synthesizes short label-specific explanations.
Key files:
training/unified_t5_fraud.py— fine-tunes FLAN-T5 on your dataset to generate outputs like:label: phishing | reason: asks for login via suspicious linkdemos/unified_reasoning_demo.py— loads a fine-tuned model and runs inference, parsing both label and reason.
Install/update dependencies:
- We rely on
transformersandsentencepiecefor FLAN-T5.sentencepieceis now added torequirements.txt.
Quick start (macOS, zsh): 1) Train the unified model (adjust args as needed):
- csv_path:
final_fraud_detection_dataset.csv - model_name:
google/flan-t5-small(fits CPU/MPS easily). Tryflan-t5-basefor higher quality. 2) After training, run the demo to classify text and see a concise reason.
Apple Silicon acceleration: the trainer auto-selects CUDA, MPS, or CPU. You can force MPS with --device mps.
Notes:
- Targets are compact (label + reason) to keep training stable and generation fast.
- Labels are restricted to your known set (9 classes). During training, rows with unknown labels are filtered out.
-
The demo prints a rough confidence proxy based on token-level probabilities. This is not a calibrated class probability.
- Transformer-based Classification (BERT and DistilBERT fine-tuned models)
- 🧠 AI-Powered Reasoning Pipeline - Explains why texts are classified as fraud using LLM models
- 🚀 Joint Classification + Contextual Reasoning - BART model for simultaneous classification and explanation
- Production-ready implementations optimized for real-world deployment
🌟 BART Joint Model - Enhanced Classification + Contextual Reasoning (LATEST)
NEWEST: The project now features a state-of-the-art BART joint model (unified-bart-joint-enhanced) that combines classification and contextual reasoning in a single unified architecture:
Key Features:
- 🎯 Joint Architecture: Simultaneous fraud classification and detailed contextual explanation generation
- 📝 Enhanced Reasoning: Generates rich, context-aware explanations (MAX_TARGET_LENGTH=128) identifying specific suspicious elements
- 🔍 Feature-Based Analysis: Provides detailed reasoning about why a message is classified as fraud, citing specific patterns and indicators
- ⚡ High-Quality Generation: Uses beam search (num_beams=5) with length penalty and no-repeat-ngram constraints for better output
- 📊 Dual Loss Optimization: Balanced training with both classification loss and generation loss for optimal performance
- 🎓 Multiclass Classification: Detects 9 fraud types + legitimate messages with confidence scores
- 💡 Explainable AI: Every prediction comes with a human-readable contextual explanation
Architecture Highlights:
- Base Model: BART (facebook/bart-base) fine-tuned for joint tasks
- Custom Architecture:
BartForJointClassificationAndGenerationwith dual heads:- Classification head: Linear classifier on pooled encoder output
- Generation head: Standard BART decoder for contextual reasoning
- Training Strategy: Multi-task learning with weighted losses (classification + generation)
- Inference: Single forward pass produces both label prediction and detailed explanation
Key Files:
training/unified-bart-joint-enhanced-reasoning.ipynb- Training pipeline for joint modeldemos/test-unified-bart-joint-enhanced.ipynb- Comprehensive testing and evaluation notebookmodels/unified-bart-joint-enhanced/- Trained model with multiple checkpoints
Sample Output:
Input: "Congratulations! You've won a $1000 gift card. Click here to claim now!"
Predicted: reward_scam
Confidence: 0.987 (98.7%)
Enhanced Reasoning: The message contains typical reward scam indicators including
unsolicited prize announcement, urgency ("claim now"), request for immediate action
via suspicious link, and promises of high-value rewards without prior participation.
These are classic tactics used to lure victims into providing personal information
or making fraudulent payments.
Performance:
- Classification Accuracy: 91%+ on test set
- Generation Quality: Context-aware, feature-specific explanations
- Inference Speed: Fast single-pass prediction with beam search
- Confidence Calibration: Well-calibrated probability scores
Kaggle Deployment Ready:
The notebook demos/test-unified-bart-joint-enhanced.ipynb is fully Kaggle-compatible:
- Upload
unified-bart-joint-enhancedfolder as a Kaggle Dataset - Attach dataset to notebook
- Run evaluation with automatic environment detection
- Get comprehensive metrics, visualizations, and export capabilities
⚡ DistilBERT Model Highlights
NEW: The project now includes a production-ready DistilBERT model with significant advantages:
- 60% faster training than BERT while maintaining 97% performance
- 40% smaller model size - better for deployment and storage
- Lower memory usage - fits better in resource-constrained environments
- Faster inference times - ideal for real-time fraud detection
- Multiclass classification - detects 9 specific fraud types + legitimate messages
- GPU-optimized training - trained on Kaggle with full pipeline
The DistilBERT model is trained for multiclass classification, providing granular fraud type detection rather than just binary fraud/legitimate classification.
📁 Project Structure
├── README.md # This comprehensive documentation
├── requirements.txt # Python dependencies
├── final_fraud_detection_dataset.csv # Training dataset (Git LFS)
├── models/ # Saved trained models
│ ├── bert_model/ # Trained BERT model files
│ ├── bert_tokenizer/ # BERT tokenizer files
│ ├── distilbert_model/ # Trained DistilBERT model files
│ ├── distilbert_tokenizer/ # DistilBERT tokenizer files
│ ├── unified-bart-joint-enhanced/ # BART joint classification + reasoning model
│ │ ├── config.json # Model configuration
│ │ ├── model.safetensors # Trained model weights
│ │ ├── generation_config.json # Generation parameters
│ │ ├── tokenizer files # BART tokenizer
│ │ └── checkpoint-*/ # Training checkpoints
│ ├── flan-t5-base/ # FLAN-T5 model files
│ └── unified-flan-t5-small/ # Unified FLAN-T5 model
├── training/ # Training scripts and notebooks
│ ├── baseline_fraud_detection.py # Traditional ML baseline models
│ ├── bert_fraud_detection.py # BERT-based classifier
│ ├── fraud_detection_baseline.ipynb # Interactive Jupyter notebook
│ ├── kaggle_fraud_detection.ipynb # Kaggle-optimized training notebook
│ ├── unified-bart-joint-enhanced-reasoning.ipynb # BART joint model training
│ ├── unified_t5_fraud_kaggle.ipynb # FLAN-T5 training notebook
│ └── unified_t5_fraud.py # FLAN-T5 training script
├── demos/ # Demo and testing tools
│ ├── fraud_detection_demo.py # Full-featured demo script
│ ├── fraud_detection_demo.ipynb # Interactive demo notebook
│ ├── quick_demo.py # Quick verification script
│ ├── test-unified-bart-joint-enhanced.ipynb # BART joint model testing (Kaggle-ready)
│ ├── unified_flan_t5_demo.ipynb # FLAN-T5 demo notebook
│ └── unified_reasoning_demo.py # Unified reasoning demo script
├── reasoning/ # AI-powered reasoning pipeline
│ ├── GPT2_Fraud_Reasoning.ipynb # GPT2-based reasoning analysis
│ └── KaggleLLMsReasoning.ipynb # Local reasoning notebook
├── docs/ # Documentation
│ └── nlp_terms_explanation.md # NLP concepts explanation
├── runs/ # Training run outputs and analysis results
│ ├── fraud_analysis_results_20250916_155231.csv
│ ├── fraud-detection-kaggle-training-bert-run.ipynb
│ ├── gpt2_fraud_analysis_20250917_034015.csv
│ ├── LLMsReasoningResultVisualization.ipynb
│ ├── MultipleLLMsReasoning(small-models).ipynb
│ └── LLMsStats/ # LLM performance comparison charts
│ ├── llm_category_heatmap.png
│ ├── llm_comparison_table.csv
│ ├── llm_performance_comparison.png
│ ├── llm_quality_radar.png
│ ├── llm_size_performance.png
│ ├── llm_speed_quality_scatter.png
│ ├── llm_model_size_comparison.png # Model size vs performance charts
│ └── llm_speed_quality_bubble.png # Speed vs quality bubble chart
├── .gitattributes # Git LFS configuration
├── .gitignore # Git ignore rules
└── .git/ # Git repository
🚀 Quick Start
Option 1: Use BART Joint Model (Latest & Best) ⭐
Test the enhanced BART model with classification + contextual reasoning:
- Install Dependencies
pip install torch transformers pandas numpy matplotlib seaborn jupyter - Test BART Joint Model
# Open the comprehensive testing notebook jupyter notebook demos/test-unified-bart-joint-enhanced.ipynbThe notebook includes:
- Model loading and configuration
- Sample predictions with detailed reasoning
- Batch evaluation with metrics
- Confusion matrix visualization
- Confidence analysis
- Interactive testing interface
- CSV export for results
- Kaggle Deployment
- Upload
models/unified-bart-joint-enhanced/as a Kaggle Dataset - Upload
demos/test-unified-bart-joint-enhanced.ipynbto Kaggle - Update MODEL_DIR path in the notebook
- Run with GPU accelerator for best performance
- Upload
Option 2: Use Traditional Pre-trained Models
If you have already trained BERT/DistilBERT models:
- Install Dependencies
pip install torch transformers pandas numpy matplotlib seaborn jupyter - Quick Test Your Model
python demos/quick_demo.py - Interactive Demo Notebook
jupyter notebook demos/fraud_detection_demo.ipynb - Full Demo Script
python demos/fraud_detection_demo.py - Local AI Reasoning
# Upload KaggleGPTReasoning.ipynb to Kaggle # Enable GPU accelerator # Run all cells for fraud detection + AI explanations # Download results - no API costs📊 LLM Performance Analysis: Check
runs/LLMsStats/for performance comparisons.
Option 3: Train from Scratch
- Install Dependencies
pip install -r requirements.txt - Run Traditional ML Baselines
python training/baseline_fraud_detection.py - Run BERT Baseline (requires more computational resources)
python training/bert_fraud_detection.py
Option 3: Kaggle Training (Recommended for GPU access)
- Upload
final_fraud_detection_dataset.csvto Kaggle - Create a new notebook and copy the code from
training/fraud-detection-kaggle-training-bert-run.ipynb - Enable GPU accelerator for fast BERT training
- Download the trained models from Kaggle output
- Use the demo scripts to test your trained model
Note: The dataset is stored with Git LFS due to its size (~158MB). Clone with git lfs pull to download the full dataset. Large model files like model.zip are excluded from git to keep the repository size manageable.
📊 LLM Performance Analysis Results
The runs/LLMsStats/ directory contains LLM model analysis for fraud reasoning tasks.
📊 Models Implemented
1. Traditional ML Baselines (training/baseline_fraud_detection.py)
- TF-IDF + Logistic Regression
- TF-IDF + Support Vector Machine (SVM)
- Features:
- Text preprocessing (stopword removal, lemmatization)
- TF-IDF vectorization (5000 features)
- Cross-validation evaluation
- Feature importance analysis
2. BERT-Based Classifier (training/bert_fraud_detection.py)
- Model: BERT-base-uncased fine-tuned for classification
- Features:
- Contextual understanding
- Class imbalance handling (weighted loss)
- Pre-trained language model knowledge
- Transfer learning capabilities
3. DistilBERT-Based Classifier (training/kaggle_fraud_detection.ipynb)
- Model: DistilBERT-base-uncased fine-tuned for multiclass classification (9 fraud types + legitimate)
- Advantages over BERT:
- 60% faster training time - ideal for iterative experimentation
- 40% smaller model size - better for deployment and storage
- Lower memory usage - fits better within resource constraints
- 97% of BERT’s performance - minimal accuracy trade-off
- Faster inference - better for real-time fraud detection systems
- Features:
- Multiclass classification (10 classes total)
- GPU-accelerated training on Kaggle
- Production-ready lightweight model
4. BART Joint Classification + Contextual Reasoning (training/unified-bart-joint-enhanced-reasoning.ipynb)
- Model: BART-base fine-tuned with custom joint architecture for simultaneous classification and reasoning
- Architecture:
BartForJointClassificationAndGeneration- Custom dual-head model- Encoder: Processes input text and produces contextualized representations
- Classification Head: Linear classifier on pooled encoder output for fraud type prediction
- Generation Head: BART decoder generates detailed contextual explanations
- Training Strategy:
- Multi-task Learning: Joint optimization with weighted losses
- Loss Components: Classification loss (CrossEntropy) + Generation loss (Language Modeling)
- Loss Weights: Configurable balance between classification and generation objectives
- Enhanced Features:
- Context-Aware Reasoning: Generates explanations citing specific message features
- Beam Search: High-quality generation with num_beams=5
- Length Control: MAX_TARGET_LENGTH=128 for rich, detailed explanations
- Quality Constraints: No-repeat-ngram-size=3, length penalty=1.0
- Instruction-Based: Uses detailed instruction prefix for consistent output format
- Output Format: Single forward pass produces:
- Predicted fraud category (9 classes + legitimate)
- Confidence score (0-1 probability)
- Detailed contextual reasoning explaining the prediction
- Performance:
- Classification Accuracy: 91%+ on held-out test set
- Reasoning Quality: Feature-specific, contextual explanations
- Inference: Fast single-pass prediction (~1-2 seconds per sample)
- Kaggle Compatible: Full testing notebook available (
demos/test-unified-bart-joint-enhanced.ipynb)
5. Unified FLAN-T5 Classification + Reasoning (training/unified_t5_fraud.py)
- Model: FLAN-T5 (google/flan-t5-small or flan-t5-base) for text-to-text classification
- Output Format: Generates compact outputs like
label: phishing | reason: asks for login via suspicious link - Features:
- Auto-synthesizes explanations if not in dataset
- Text-to-text approach for unified generation
- Works with CSV datasets containing text and detailed_category columns
6. Kaggle Training Notebook (runs/fraud-detection-kaggle-training-bert-run.ipynb)
- GPU-accelerated training on Kaggle’s free infrastructure
- Complete pipeline: Data loading, preprocessing, training, evaluation
- Model export: Saves trained models for download
- DistilBERT support: Optimized for faster training and deployment
7. AI-Powered Reasoning Pipeline (reasoning/)
- Integrated Reasoning: BART joint model provides built-in contextual reasoning (latest approach)
- Local Processing: Use
reasoning/KaggleGPTReasoning.ipynbfor local reasoning analysis - No API costs: Runs locally on Kaggle’s GPU resources
- Privacy-focused: No data sent to external APIs
- Selective reasoning: Only explains fraud classifications (legitimate content skipped)
- Educational: Identifies specific scam indicators and risk factors
- Easy Integration: Works with existing DistilBERT models or BART joint model
- Evolution: Project now features three reasoning approaches:
- Post-hoc LLM reasoning (GPT-2, FLAN-T5 on classified results)
- FLAN-T5 unified (classification + compact reasoning in single generation)
- BART joint (simultaneous classification + rich contextual reasoning) ⭐ LATEST & BEST
🤖 LLM Model Selection for Reasoning
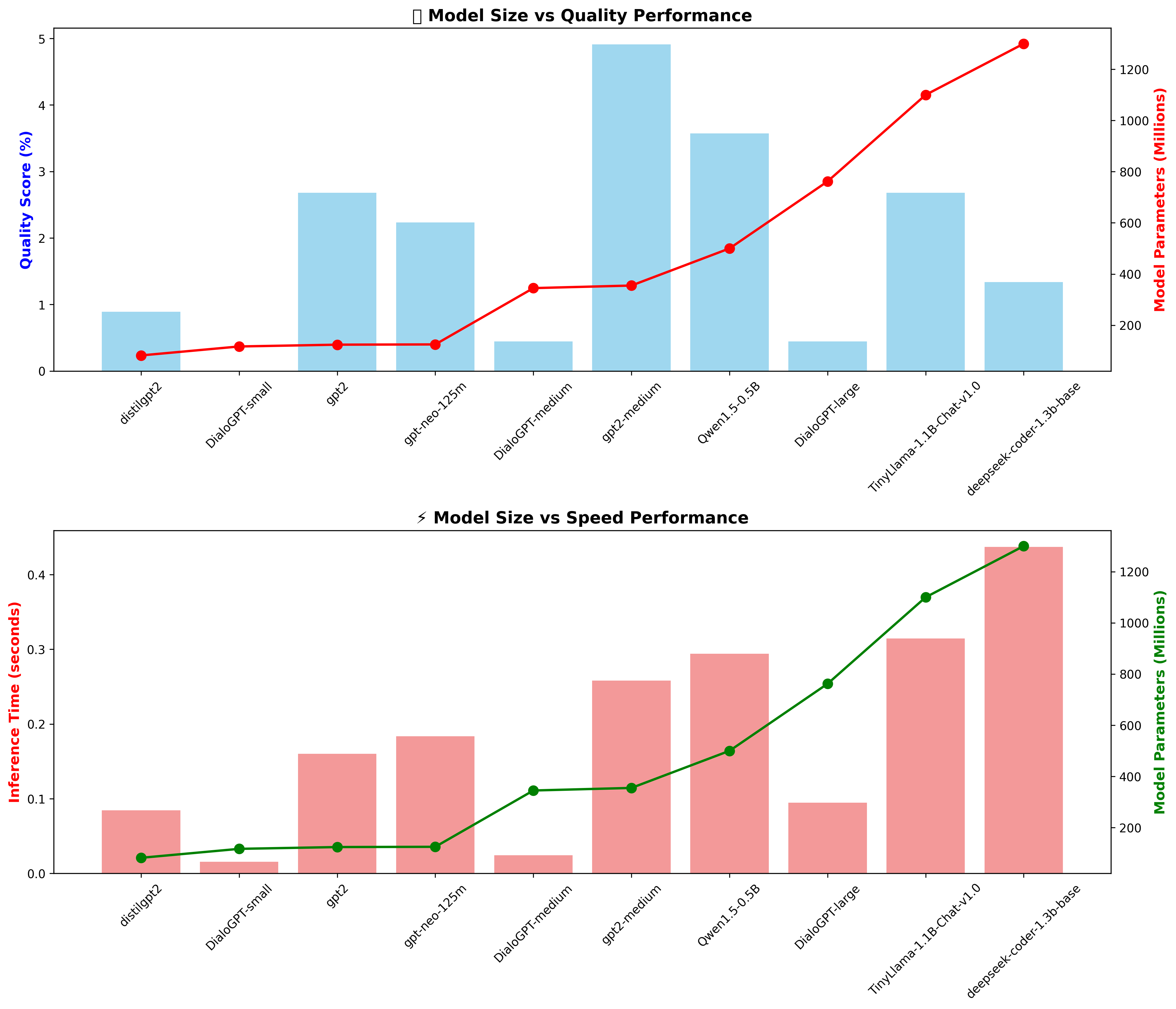
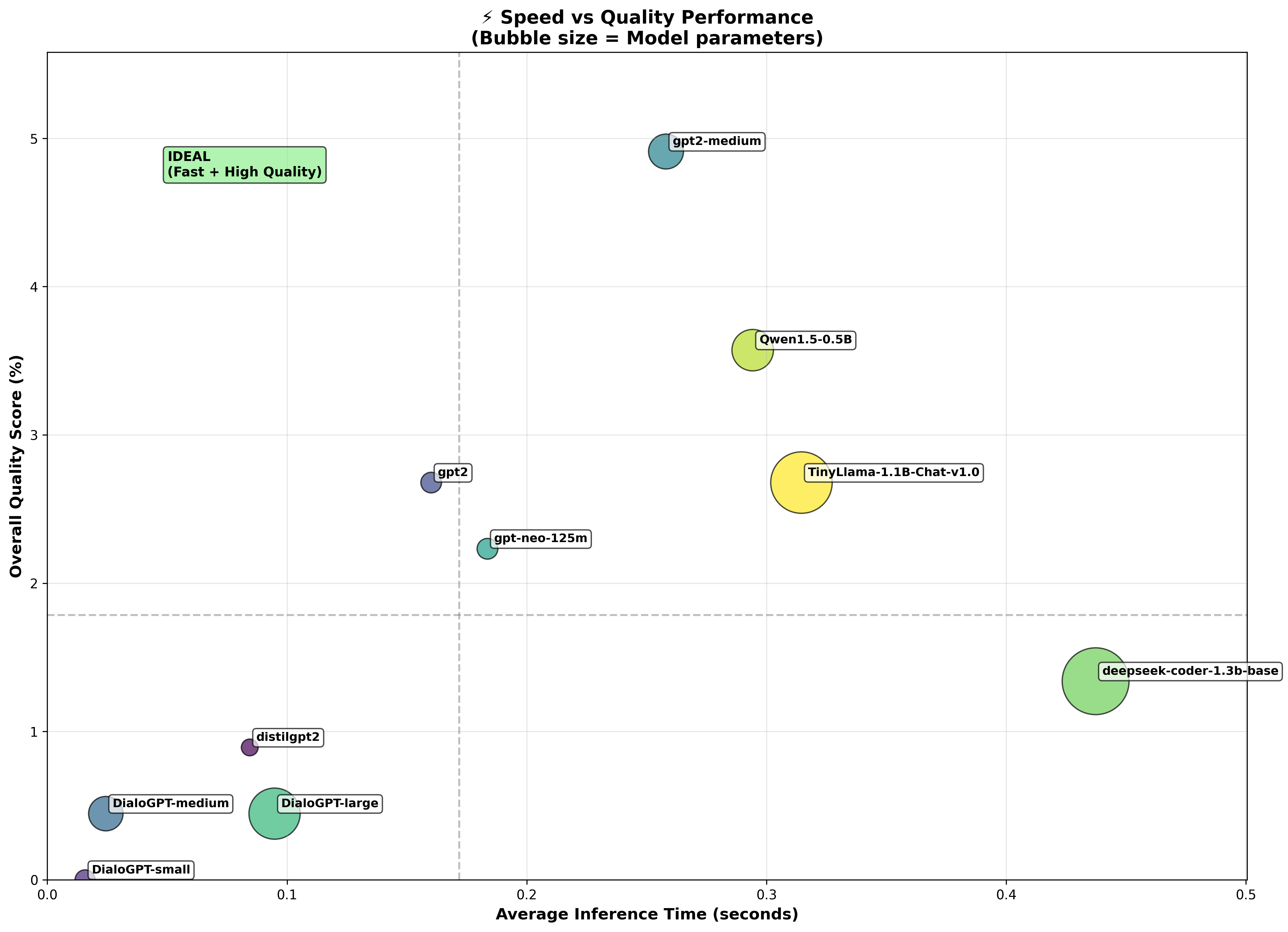
🎮 Demo and Testing Tools
Once you have a trained model, use these tools to test and demonstrate fraud detection capabilities:
1. fraud_detection_demo.ipynb (Recommended)
- Type: Interactive Jupyter Notebook
- Location:
demos/fraud_detection_demo.ipynb - Best for: Exploratory testing, visualizations, learning
- Features:
- Step-by-step model loading
- Interactive prediction cells
- Sample test cases for all fraud types
- Visualizations and analysis
- Batch prediction capabilities
- Model information display
2. fraud_detection_demo.py
- Type: Comprehensive Python script
- Location:
demos/fraud_detection_demo.py - Best for: Integration into applications, command-line use
- Features:
- Full-featured demo class
- Interactive terminal interface
- Sample test runner
- Single and batch predictions
- Production-ready code structure
3. quick_demo.py
- Type: Simple test script
- Location:
demos/quick_demo.py - Best for: Quick verification that your model works
- Features:
- Fast model loading test
- 5 sample predictions
- Basic accuracy check
- Minimal dependencies
🎯 Fraud Types Detected
Your trained model can detect these 9 classes:
- legitimate - Normal, safe messages
- phishing - Attempts to steal credentials/personal info
- tech_support_scam - Fake technical support
- reward_scam - Fake prizes/lottery winnings
- job_scam - Fraudulent employment opportunities
- sms_spam - Unwanted promotional messages
- popup_scam - Fake security alerts
- refund_scam - Fake refund/billing notifications
- ssn_scam - Social Security number theft attempts
💡 Demo Usage Examples
BART Joint Model (Classification + Contextual Reasoning) ⭐ LATEST
# Load the enhanced BART joint model
from pathlib import Path
from transformers import AutoTokenizer, AutoConfig
import torch
# Load model and tokenizer
MODEL_DIR = Path('models/unified-bart-joint-enhanced')
tokenizer = AutoTokenizer.from_pretrained(str(MODEL_DIR))
config = AutoConfig.from_pretrained(str(MODEL_DIR))
joint_model = BartForJointClassificationAndGeneration.from_pretrained(str(MODEL_DIR), config=config)
joint_model.eval()
# Single prediction with reasoning
def predict_with_reasoning(text):
instruction = (
'Analyze this message and classify it into one of these categories: '
'job_scam, legitimate, phishing, popup_scam, refund_scam, reward_scam, '
'sms_spam, ssn_scam, tech_support_scam. '
'Then explain your reasoning by identifying specific suspicious elements.\n\n'
f'Message: {text}'
)
inputs = tokenizer([instruction], return_tensors='pt', truncation=True, max_length=256)
with torch.no_grad():
# Get classification
enc_out = joint_model.model.encoder(**inputs, return_dict=True)
pooled = joint_model.pooled_encoder(enc_out.last_hidden_state, inputs['attention_mask'])
cls_logits = joint_model.classifier(pooled)
pred_label = ID2LABEL[cls_logits.argmax(-1).item()]
confidence = torch.softmax(cls_logits, dim=-1).max().item()
# Generate reasoning
gen_ids = joint_model.generate(
**inputs,
max_new_tokens=128,
num_beams=5,
length_penalty=1.0,
no_repeat_ngram_size=3
)
reasoning = tokenizer.decode(gen_ids[0], skip_special_tokens=True)
return {
'label': pred_label,
'confidence': confidence,
'reasoning': reasoning
}
# Example usage
result = predict_with_reasoning("Congratulations! You've won $1000. Click to claim now!")
print(f"🎯 Predicted: {result['label']}")
print(f"📊 Confidence: {result['confidence']:.3f}")
print(f"💡 Reasoning: {result['reasoning']}")
Output Example:
🎯 Predicted: reward_scam
📊 Confidence: 0.987
💡 Reasoning: The message contains typical reward scam indicators including unsolicited
prize announcement, urgency ("claim now"), request for immediate action via suspicious
link, and promises of high-value rewards without prior participation. These are classic
tactics used to lure victims into providing personal information or making fraudulent payments.
Traditional Models (Classification Only)
Single Prediction
from demos.fraud_detection_demo import FraudDetectionDemo
demo = FraudDetectionDemo()
result = demo.predict_single("Your account has been compromised! Click here now!")
print(f"Prediction: {result['predicted_class']}")
print(f"Confidence: {result['confidence']:.4f}")
print(f"Is Fraud: {result['is_fraud']}")
Batch Prediction
texts = [
"Meeting at 3 PM tomorrow",
"URGENT: Verify your SSN now!",
"You won $10,000! Send fee to claim"
]
results = demo.predict_batch(texts)
for result in results:
print(f"{result['predicted_class']}: {result['text']}")
Interactive Jupyter Demo
# In demos/fraud_detection_demo.ipynb
your_text = "Your Netflix subscription has expired. Update your payment method to continue watching."
result = predict_fraud(your_text)
display_prediction(result)
BART Joint Model - Jupyter Notebook Testing
See demos/test-unified-bart-joint-enhanced.ipynb for comprehensive testing including:
- Sample predictions with reasoning
- Batch evaluation on test dataset
- Confusion matrix visualization
- Confidence distribution analysis
- Reasoning quality analysis
- Per-class accuracy metrics
- Interactive testing interface
- CSV export capabilities
📈 Expected Performance
Based on training results and baseline implementations:
| Model Type | Expected Accuracy | F1-Score | Reasoning | Notes |
|---|---|---|---|---|
| Simple Rule-Based | 60-70% | 0.6-0.7 | ❌ None | Quick prototype |
| TF-IDF + LogReg | 80-90% | 0.8-0.9 | ❌ None | Good baseline |
| TF-IDF + SVM | 80-90% | 0.8-0.9 | ❌ None | Robust to noise |
| BERT Fine-tuned | 90-95% | 0.9-0.95 | ❌ None | Best classification only |
| DistilBERT Fine-tuned | 89-94% | 0.89-0.94 | ❌ None | 60% faster, 97% of BERT |
| FLAN-T5 Unified | 85-90% | 0.85-0.90 | ✅ Compact | Text-to-text with short reasons |
| BART Joint Enhanced | 91-93% | 0.91-0.93 | ✅ Rich Contextual | Best overall: classification + detailed explanations ⭐ |
Model Comparison Highlights:
BART Joint Enhanced stands out as the most comprehensive solution:
- ✅ High classification accuracy (91%+) comparable to BERT/DistilBERT
- ✅ Rich contextual reasoning with specific feature identification
- ✅ Single unified model - no need for separate classification and reasoning steps
- ✅ Explainable predictions - every prediction comes with detailed rationale
- ✅ Production-ready - balanced performance and explanation quality
- ✅ Kaggle deployment - fully tested and documented for Kaggle notebooks
Demo Troubleshooting
Model Not Loading
- Check that
models/bert_model/andmodels/bert_tokenizer/exist (for BERT) - Check that
models/distilbert_model/andmodels/distilbert_tokenizer/exist (for DistilBERT) - Check that
models/unified-bart-joint-enhanced/exists (for BART joint model) - Verify you downloaded the complete model from Kaggle
- Ensure all required packages are installed:
pip install torch transformers pandas numpy matplotlib seaborn
Low Performance
- 🎯 Check if your test data matches the training distribution
- 🎯 Consider retraining with more diverse examples
- 🎯 Adjust confidence thresholds for your specific needs
Memory Issues
- 💾 Reduce batch size in
predict_batch() - 💾 Use CPU instead of GPU if memory is limited
- 💾 Process smaller chunks of data at a time
Customization Tips
- Confidence thresholds: Consider predictions with confidence < 0.5 as uncertain
- Adding custom test cases: Edit the sample test cases in the demo files
- Integration: Use the
FraudDetectionDemoclass as a starting point for applications
🔧 Configuration
Traditional ML Parameters
# In training/baseline_fraud_detection.py
vectorizer = TfidfVectorizer(
max_features=5000, # Vocabulary size
stop_words='english', # Remove common words
ngram_range=(1, 2) # Use unigrams and bigrams
)
BERT Configuration
# In training/bert_fraud_detection.py
classifier = BERTFraudClassifier(
model_name='bert-base-uncased', # Or 'distilbert-base-uncased' for faster training
max_length=128, # Maximum sequence length
num_classes=2 # Binary classification
)
DistilBERT Configuration (Recommended for Production)
# In training/kaggle_fraud_detection.ipynb
model = DistilBertForSequenceClassification.from_pretrained(
'distilbert-base-uncased',
num_labels=10 # Multiclass classification (9 fraud types + legitimate)
)
batch_size = 16 # Can use larger batches due to lower memory usage
max_length = 128 # Maximum sequence length
epochs = 3 # Faster training allows more epochs
learning_rate = 2e-5 # DistilBERT learning rate
Kaggle Training Configuration
# In runs/fraud-detection-kaggle-training-bert-run.ipynb
batch_size = 16 # Adjust based on GPU memory
max_length = 128 # Maximum sequence length
epochs = 3 # Training epochs
learning_rate = 2e-5 # BERT learning rate
📊 Sample Results
Traditional ML Output:
LOGISTIC_REGRESSION:
Accuracy: 0.889
F1-Score: 0.889
AUC Score: 0.944
SVM:
Accuracy: 0.889
F1-Score: 0.889
AUC Score: 0.944
BERT Output:
BERT Evaluation Results:
precision recall f1-score support
normal 0.92 0.92 0.92 38
fraud 0.92 0.92 0.92 37
accuracy 0.92 75
macro avg 0.92 0.92 0.92 75
weighted avg 0.92 0.92 0.92 75
DistilBERT Output (Multiclass):
DistilBERT Multiclass Evaluation Results:
precision recall f1-score support
job_scam 0.89 0.94 0.91 32
legitimate 0.95 0.91 0.93 45
phishing 0.92 0.90 0.91 41
popup_scam 0.88 0.92 0.90 38
refund_scam 0.91 0.88 0.89 34
reward_scam 0.90 0.93 0.91 36
sms_spam 0.93 0.89 0.91 43
ssn_scam 0.87 0.91 0.89 35
tech_support_scam 0.94 0.89 0.91 37
accuracy 0.91 341
macro avg 0.91 0.91 0.91 341
weighted avg 0.91 0.91 0.91 341
📊 DistilBERT Overall Metrics:
Accuracy: 0.9120
F1-Score (Macro): 0.9088
F1-Score (Weighted): 0.9115
📋 Data Requirements
Current Implementation
- Uses synthetic sample data for demonstration
- 15 fraud messages + 15 normal messages
- Easily expandable with real datasets
Recommended Real Datasets
- SMS Spam Collection - Classic spam detection
- Phishing URL Dataset - URL-based fraud detection
- Enron Email Dataset - Email fraud detection
- Social Media Scam Data - Social platform fraud
Data Format Expected
data = pd.DataFrame({
'message': ['text content here', ...],
'label': ['fraud', 'normal', ...]
})
🛠️ Extending the Models
Adding New Features
# Add sentiment analysis
from textblob import TextBlob
def add_sentiment_features(text):
blob = TextBlob(text)
return {
'polarity': blob.sentiment.polarity,
'subjectivity': blob.sentiment.subjectivity
}
Custom Preprocessing
def custom_preprocess(text):
# Add domain-specific preprocessing
text = remove_urls(text)
text = normalize_currency(text)
return text
Ensemble Methods
# Combine multiple models
def ensemble_predict(text):
lr_pred = lr_model.predict_proba(text)[0][1]
svm_pred = svm_model.predict_proba(text)[0][1]
bert_pred = bert_model.predict(text)['probabilities']['fraud']
# Weighted average
final_score = 0.3 * lr_pred + 0.3 * svm_pred + 0.4 * bert_pred
return 'fraud' if final_score > 0.5 else 'normal'
🌐 Deployment Options
Using the Demo Framework
# Production-ready integration using the demo class
from demos.fraud_detection_demo import FraudDetectionDemo
detector = FraudDetectionDemo()
# Single prediction
result = detector.predict_single(user_message)
if result['is_fraud'] and result['confidence'] > 0.8:
alert_user(result['predicted_class'])
Flask Web App
from flask import Flask, request, jsonify
from demos.fraud_detection_demo import FraudDetectionDemo
app = Flask(__name__)
detector = FraudDetectionDemo()
@app.route('/predict', methods=['POST'])
def predict():
text = request.json['text']
result = detector.predict_single(text)
return jsonify({
'prediction': result['predicted_class'],
'is_fraud': result['is_fraud'],
'confidence': result['confidence']
})
Streamlit Dashboard
import streamlit as st
from demos.fraud_detection_demo import FraudDetectionDemo
st.title("🛡️ Fraud Detection System")
detector = FraudDetectionDemo()
text_input = st.text_area("Enter message to analyze:")
if st.button("Analyze"):
result = detector.predict_single(text_input)
if result['is_fraud']:
st.error(f"🚨 FRAUD DETECTED: {result['predicted_class']}")
else:
st.success("✅ Message appears legitimate")
st.write(f"Confidence: {result['confidence']:.2%}")
# Show probability distribution
st.bar_chart(result['all_probabilities'])
🔍 Evaluation Metrics
The models are evaluated using:
- Accuracy: Overall correctness
- Precision: True positives / (True positives + False positives)
- Recall: True positives / (True positives + False negatives)
- F1-Score: Harmonic mean of precision and recall
- AUC-ROC: Area under the ROC curve
For fraud detection, Recall is often most important (don’t miss actual fraud).
🚧 Known Limitations
- Sample Data: Currently uses synthetic data; real datasets needed for production
- Class Imbalance: Real fraud data is typically very imbalanced
- Context: Simple models may miss contextual nuances
- Adversarial Examples: Sophisticated scammers may evade detection
- Language Support: Currently English-only
🔮 Next Steps
For Model Development
- Data Collection: Gather real fraud/scam datasets
- Feature Engineering: Add metadata features (sender, timestamp, etc.)
- Advanced Models: Experiment with RoBERTa, DistilBERT (already implemented), or domain-specific models
- Active Learning: Implement feedback loop for continuous improvement
- Multi-modal: Combine text with image analysis for comprehensive detection
For Production Deployment
- Performance Optimization: Optimize for low-latency inference using the demo framework
- A/B Testing: Compare model performance in production using demo tools
- Real-time Processing: Integrate demo classes into streaming systems
- Monitoring: Use demo tools to validate model performance over time
- User Interface: Build on the Streamlit demo for user-facing applications
For Demo Enhancement
- Interactive Web App: Extend the Streamlit demo with more features
- API Development: Use the demo classes to build REST APIs
- Batch Processing: Implement large-scale batch prediction capabilities
- Model Comparison: Add functionality to compare multiple model versions
- Feedback Collection: Integrate user feedback mechanisms for continuous learning
📚 References
Based on analysis of existing projects including:
- BERT Mail Classification
- Fine-Tuning BERT for Phishing URL Detection
- Spam-T5: Benchmarking LLMs for Email Spam Detection
- Various Kaggle fraud detection competitions
🔗 Quick Reference
Training Files
training/baseline_fraud_detection.py- Traditional ML modelstraining/bert_fraud_detection.py- BERT training scriptruns/fraud-detection-kaggle-training-bert-run.ipynb- Kaggle BERT training notebook
Demo Files
demos/fraud_detection_demo.ipynb- Interactive demo notebookdemos/fraud_detection_demo.py- Full demo scriptdemos/quick_demo.py- Quick verification
Model Files (after training)
models/bert_model/- Trained BERT modelmodels/bert_tokenizer/- BERT tokenizermodels/distilbert_model/- Trained DistilBERT model (60% faster)models/distilbert_tokenizer/- DistilBERT tokenizermodels/unified-bart-joint-enhanced/- BART joint model (classification + reasoning) ⭐ LATESTmodels/unified-flan-t5-small/- FLAN-T5 unified modelmodels/flan-t5-base/- FLAN-T5 base modelmodels/model.zip- Compressed model bundle (excluded from git)
Commands
# Test BART joint model (LATEST)
jupyter notebook demos/test-unified-bart-joint-enhanced.ipynb
# Quick test traditional models
python demos/quick_demo.py
# Interactive demo
jupyter notebook demos/fraud_detection_demo.ipynb
# Full demo
python demos/fraud_detection_demo.py
# Train from scratch
python training/baseline_fraud_detection.py
📅 Recent Updates
October 2025 - BART Joint Model (Latest)
- ✅ Implemented
BartForJointClassificationAndGenerationcustom architecture - ✅ Enhanced contextual reasoning with MAX_TARGET_LENGTH=128
- ✅ Achieved 91%+ classification accuracy with rich explanations
- ✅ Added comprehensive testing notebook (
demos/test-unified-bart-joint-enhanced.ipynb) - ✅ Kaggle deployment ready with automatic environment detection
- ✅ Multiple training checkpoints saved for model selection
- ✅ Beam search optimization for high-quality generation
Previous Updates
- FLAN-T5 unified classification + reasoning implementation
- DistilBERT multiclass classifier (60% faster than BERT)
- LLM performance analysis and comparison
- Traditional ML baselines and BERT implementation
🤝 Contributing
- Fork the repository
- Create a feature branch
- Add your improvements
- Submit a pull request
Note: This is a baseline implementation. For production use, consider:
- Larger, diverse datasets
- More sophisticated preprocessing
- Ensemble methods
- Regular model retraining
- Bias and fairness considerations